Il CORPUS PRIMULA è un corpus ristretto di voci calabresi ideato e creato presso il Laboratorio di Fonetica dell’Università della Calabria per la valutazione delle metodologie e dei sistemi di riconoscimento del parlatore con particolare attenzione all’ambito forense. Lo scopo vuole essere quello di costituire una base comune sulla quale misurare le tecniche e le metodologie utilizzate in ambito di Speaker Recognition.
DESCRIZIONE
Ciò che caratterizza PRIMULA è la modalità con cui lo stesso è stato creato. Durante la fase di ideazione del CORPUS e successivamente durante la fase di acquisizione dello stesso si è ritenuto di dover simulare una situazione reale al fine di avere, a prodotto finito, situazioni simili o quantomeno assai vicine a quelle che si presentano di norma nella maggior parte dei casi forensi. Proprio in virtù di ciò una parte delle registrazioni è stata effettuata con attrezzature normalmente utilizzate per le intercettazioni (grazie all’ausilio di alcuni Commissariati di Polizia e ditte private normalmente utilizzate nelle fasi di intercettazione dagli organi inquirenti). È stato così possibile registrare contemporaneamente ed in parallelo lo stesso materiale prodotto attraverso la microspia installata su un’autovettura e attraverso un cellulare collegato con un telefono fisso. Tale materiale registrato costituisce una intercettazione “ambientale” (in automobile) e una registrazione telefonica (tra utenza cellulare e utenza di rete fissa). Il corpus contiene poi, una serie di registrazioni di “controllo” in condizioni differenti.
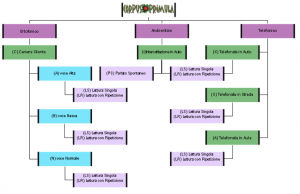
Il CORPUS PRIMULA consta di oltre 900 files raggruppati in 5 tipologie di registrazione C (Camera silente), A (telefonata in Aula), S (telefonata in Strada), I (Intercettazione in auto) e X (telefonata in auto) per 4 parlatori di sesso maschile AM, LR, SC, VG con tipologie di produzione differenti sia di parlato letto che di parlato spontaneo (sia in dialetto calabrese che italiano regionale).
Tutti i file sono in formato *.wav PCM 8kHz – 16 bit – mono per emulare le registrazioni della microspia aventi caratteristiche peggiori in termini qualitativi.
Il CORPUS è diviso in 4 directory (una per parlatore). Ciascuna directory contiene delle sottodirectory che contengono i rispettivi ITEM. Una descrizione dettagliata degli ITEM viene fornita in appendice.
Il CORPUS è stato controllato manualmente.
CODIFICA NOME FILE
Nel nome dei file che compongono il presente CORPUS risultano codificate tutte le informazioni disponibili e risulta standardizzato secondo il seguente schema a sei campi secondo la sintassi [xx]_[a]_[b]_[c(d)]_[e].wav dove:
[xx] = campo di due lettere che corrisponde alle iniziali del nome e del cognome del parlatore:
AM
LR
SC
VG
[a] = tipologia di registrazione che identifica, oltre al canale di registrazione utilizzato, anche la qualità del segnale corrispondente:
C (registrazione in Camera silente)
A (registrazione di telefonata in Aula)
S (registrazione di telefonata in Strada)
I (Intercettazione in auto)
X (registrazione di telefonata in auto)
[b] = modo di fonazione che identifica il tono di voce con cui il soggetto parla:
B (voce Bassa)
N (voce Normale)
A (voce Alta)
[c] = tipologia di produzione che identifica il materiale cui la produzione del soggetto fa riferimento:
LR (Lettura con Ripetizione)
LS (Lettura Singola)
PS (Parlato Spontaneo)
(d) = identificativo della frase ripetuta solo nel caso in cui [c] = “LR”:
1 (frase 1)
2 (frase 2)
3 (frase 3)
[e] = numero da 01, 02, 03…10 che:
nel caso di [c] = LS corrisponde all’identificativo della frase pronunciata
nel caso di [c] = LR corrisponde al numero della ripetizione della frase contrassegnata da (d) che in alcuni casi può essere inferiore o maggiore a 10
nel caso di [c] = PS corrisponde all’occorrenza di parlato spontaneo
Esempi:
[xx]_[a]_[b]_[c(d)]_[e].wav = VG_I_N_LR3_07.wav che sta per la registrazione di “VG” con intercettazione in auto (I), con tono di voce normale (N), della ripetizione “07” della frase ripetuta LR3.
[xx]_[a]_[b]_[c]_[e].wav = VG_I_N_PS_02.wav che sta per la registrazione di “VG” con intercettazione in auto (I), con tono di voce normale (N) dell’occorrenza nr. “02” del parlato spontaneo (PS).
[xx]_[a]_[b]_[c]_[e].wav = VG_C_A_LS_05.wav che sta per la registrazione di “VG” in camera silente (C) con tono di voce alto (A) della frase singola (LS) numero “05”.
NOTA: come più sopra accennato per le tipologie di registrazione “I” (Intercettazione in auto) e “X” (registrazione di telefonata in auto) i file sono identici ed allineati, ovvero registrati nel medesimo istante, quando per lo stesso parlatore [xx] il contenuto che segue “I” e “X” corrisponde come negli esempi di seguito riportati:
VG_I_N_LS_05 = VG_X_N_LS_05
VG_I_N_LR3_06 = VG_X_N_LR3_06
APPENDICE
Nella sezione che segue vengono descritti gli ITEM che compongono il CORPUS PRIMULA.
Per il parlato spontaneo (PS) la conversazione (tra due o più persone) non ha avuto argomenti prestabiliti ed è libera da qualsiasi inibizione (trattasi infatti di situazioni reali) ed è registrato in autovettura attraverso microspia (con sistema di intercettazione MCR) a 8KHz – 8 bit Mono – CCITT A-LAW convertito poi in formato wav PCM per facilitarne le analisi strumentali. Al numero che segue “PS” che indica l’occorrenza di parlato spontaneo può, dove disponibile, seguire la dicitura “in” o “out” che rappresentano, rispettivamente, registrazione avvenuta con il locutore in autovettura o registrazione avvenuta con il locutore all’esterno dell’autovettura.
Per il parlato letto i parlatori hanno letto due liste di frasi in condizioni differenti. Per la prima lista (LR) è stato chiesto ai soggetti di leggere tre frasi (1, 2, 3) per 10 (01, 02, 03…10) volte consecutive (in alcuni casi le ripetizioni possono essere 5 invece che 10). Per la seconda lista (LS) è stato chiesto ai soggetti di leggere 10 frasi (01, 02, 03…10) una volta soltanto. I codici anteposti alle frasi corrispondo ai criteri di codifica adottati e sopra descritti.
LISTA 1 – Frasi da ripetere per dieci volte
[c] = LR; (d) = 1; [e]= 01, 02, 03…10; Una recente statistica rivela che metà dei bambini tedeschi possiede due cellulari.
[c] = LR; (d) = 2; [e]= 01, 02, 03…10; La fonetica si occupa dei fenomeni fonici del linguaggio nonché dei processi delle loro singole produzioni.
[c] = LR; (d) = 3; [e]= 01, 02, 03…10; Le sillabe sono le strutture più elementari che stanno come base di ciascun raggruppamento di fonemi.
LISTA 2 – Frasi da leggere una volta sola
[c] = LS; [e] = 01; Il progresso tecnologico progredisce con ritmi frenetici.
[c] = LS; [e] = 02; Sono consapevole delle sanzioni penali previste dalla legge 18.
[c] = LS; [e] = 03; Il collegio sindacale deve riunirsi quattro volte l’anno per decidere sui progetti da presentare.
[c] = LS; [e] = 04; É cosa risaputa che il comune sale da cucina risulti costituito da cristalli di cloruro di sodio.
[c] = LS; [e] = 05; Non tutti sanno che la superficie lunare si presenta costellata di crateri di varia dimensione.
[c] = LS; [e] = 06; A causa dei rincari del petrolio molti dei trasporti su gomma rischiano la paralisi.
[c] = LS; [e] = 07; Anche questa primavera le rondini sono tornate dai paesi lontani seguendo percorsi migratori noti.
[c] = LS; [e] = 08; Ho sempre sognato di diventare pilota per inoltrami nello spazio cosmico che ci circonda.
[c] = LS; [e] = 09; Solo dopo la laurea mi sono reso conto che per diventare dottori bisogna fare tanti sacrifici.
[c] = LS; [e] = 10; Sul davanzale della finestra sono cresciute delle bellissime piantine di basilico.
Le registrazioni in Camera Silente sono avvenute in tre diverse modalità: Voce Alta, Voce Normale e Voce Bassa. La Voce Alta, è stata ottenuta facendo ascoltare della musica in cuffia al locutore durante la fase di registrazione, spingendolo quindi per un naturale processo di Feed-Back ad aumentare il volume della propria voce.
STRUTTURAZIONE E ORGANIZZAZIONE DEL CORPUS